




Page suivante: 3 Cartographie Niveau précédent: Satisfaction de contraintes et Page précédente: 1 Introduction
Page suivante: 3 Cartographie
Niveau précédent: Satisfaction de contraintes et
Page précédente: 1 Introduction
Dans la plupart des cellules, le programme génétique est détenu par un
ensemble de molécules géantes, les Acides DésoxyriboNucléiques (ADN),
contenues dans les chromosomes. Dans une molécule d'ADN, les
caractéristiques d'un organisme sont codées dans l'enchaînement de petites
molécules appelées nucléotides composées d'un groupe phosphate, d'un
groupe sucre et d'une base azotée ( Adénine, Thymine,
Guanine ou Cytosine) et attachées entre elles par des liaisons dites
covalentes. On représente couramment une telle molécule par une chaîne orientée de
caractères pris dans un alphabet à 4 caractères 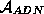 = {A,
T, G, C}, chacun désignant le type de la base appartenant au nucléotide.
= {A,
T, G, C}, chacun désignant le type de la base appartenant au nucléotide.
C'est l'association de paires de brins complémentaires d'ADN enroulés en hélice
qui constitue le génome de la plupart des organismes. Dans le génome,
certaines portions, les gènes, fixent les caractéristiques des
organismes. L'ensemble des gènes d'un organisme est appelé génotype,
le phénotype désignant la manifestation physique du génotype. Un
caractère phénotypique est par exemple la couleur des yeux. L'existence de
plusieurs formes alternatives d'un gène induit un polymorphisme
génétique. Les formes alternatives d'un gène sont appelées allèles
(par exemple, pour le gène A << couleur des cheveux >>
: blonds 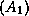 ou bruns
ou bruns 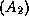 ; pour le gène B << couleur des yeux
>> : bleus
; pour le gène B << couleur des yeux
>> : bleus 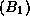 ou marrons
ou marrons 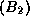 ).
).
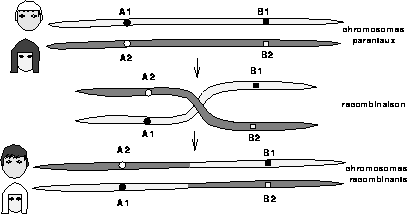
Figure 1: Représentation schématique d'un événement de recombinaison entre
deux chromosomes homologues. Les phénotypes sont représentés à gauche :
cheveux blonds et yeux clairs, cheveux bruns et yeux foncés pour les
phénotypes parentaux ; cheveux bruns et yeux clairs, cheveux blonds et
yeux foncés pour les recombinants.
Le programme génétique est transmis dans sa totalité aux générations successives de cellules. C'est à ce moment là que peuvent se produire, parfois, des recombinaisons génétiques (cf. Figure 1), c'est-à-dire des échanges aléatoires symétriques de matériel génétique entre chromosomes de même type, l'un provenant du père, l'autre de la mère. Ces événements impliquent le réarrangement de domaines entiers du génome contribuant ainsi à la variabilité génétique.
La taille d'un génome peut varier de quelques 5 000 nucléotides pour des
organismes très simples tels certains virus, à quelques 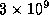 nucléotides pour le génome humain. On comprend dès lors que le décryptage
de ce code en un ensemble de caractéristiques d'un organisme soit très
complexe. Les technologies actuelles permettent aujourd'hui (ce n'était pas
vrai il y a à peine quelques 10 ans) d'envisager ce décryptage pour un
organisme donné, l'objectif ultime se ramenant, pour
de nombreux biologistes, à un problème de cartographie consistant à
positionner, tout le long du génome, un certain nombre de marques
représentatives ou non de caractères phénotypiques : les marqueurs
génétiques.
nucléotides pour le génome humain. On comprend dès lors que le décryptage
de ce code en un ensemble de caractéristiques d'un organisme soit très
complexe. Les technologies actuelles permettent aujourd'hui (ce n'était pas
vrai il y a à peine quelques 10 ans) d'envisager ce décryptage pour un
organisme donné, l'objectif ultime se ramenant, pour
de nombreux biologistes, à un problème de cartographie consistant à
positionner, tout le long du génome, un certain nombre de marques
représentatives ou non de caractères phénotypiques : les marqueurs
génétiques.
L'ADN représente le matériel génétique de la plupart des êtres. Il renferme
l'information nécessaire pour la synthèse des protéines, grosses
molécules qui constituent, en quelque sorte, l'expression de la traduction
du code génétique. Une protéine est un assemblage réalisé à partir de 20
molécules différentes plus petites, les acides aminés et sa taille
peut varier de quelques dizaines à plusieurs milliers d'acides aminés. On
appelle aussi peptide une chaîne contenant un petit nombre d'acides
aminés. Chaque protéine existe sous une conformation unique qui est définie
par différents niveaux structuraux. La séquence orientée des acides aminés
liés dans la chaîne polypeptidique constitue la structure primaire de
la protéine. Si l'on examine la structure plus fine du repliement de la
chaîne, on voit que des segments relativement étendus de la chaîne
polypeptidique adoptent des structures régulières. Il s'agit de l'hélice
 et du feuillet
et du feuillet 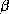 . Une chaîne polypeptidique repliée en hélice
. Une chaîne polypeptidique repliée en hélice
 a une trajectoire hélicoïdale. Un feuillet
a une trajectoire hélicoïdale. Un feuillet 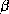 a une structure
polypeptidique presque plate (cf. Figure 2) .
a une structure
polypeptidique presque plate (cf. Figure 2) .
Figure 2: Structure d'une hélice  (à gauche) et d'un feuillet
(à gauche) et d'un feuillet
 (à droite). Le feuillet
(à droite). Le feuillet  est composé de 3 brins
est composé de 3 brins 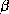 .
L'orientation des brins est donnée par les flèches aux extrémités.
.
L'orientation des brins est donnée par les flèches aux extrémités.
La plus grande partie d'une chaîne polypeptidique consiste en une succession
d'hélices  et de feuillets
et de feuillets  réunis par des demi-tours ou des
boucles à la surface de la protéine (cf. Figure 3). Les
hélices, les feuillets et les boucles déterminent ce que l'on appelle la
structure secondaire des protéines. La structure finale, c'est-à-dire
l'organisation des éléments de la structure secondaire entre eux est appelée
structure tertiaire de la protéine.
réunis par des demi-tours ou des
boucles à la surface de la protéine (cf. Figure 3). Les
hélices, les feuillets et les boucles déterminent ce que l'on appelle la
structure secondaire des protéines. La structure finale, c'est-à-dire
l'organisation des éléments de la structure secondaire entre eux est appelée
structure tertiaire de la protéine.
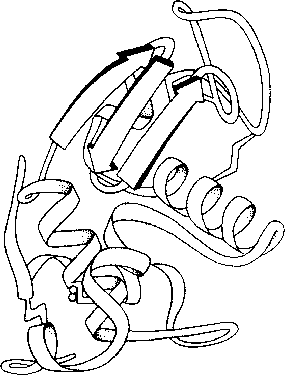
Figure 3: Représentation schématique de la structure tertiaire d'une protéine
Les Acides Ribonucléiques (ARN) sont l'un des autres constituants
essentiels des organismes vivants. Une molécule d'ARN est, comme l'ADN,
constituée à partir d'un ensemble de 4 nucléotides. Cependant, les deux
molécules se différencient par le groupe sucre ( désoxyribose pour
l'ADN et ribose pour l'ARN) et par l'une des 4 bases : Thymine pour
l'ADN, Uracile pour l'ARN. Comme l'ADN, une molécule d'ARN est
couramment représentée par une chaîne orientée de caractères pris dans un
alphabet à 4 caractères 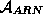 = {A, U, G, C}, chaque
caractère étant spécifique de la base d'un nucléotide. Le type d'un
nucléotide étant entièrement caractérisé par sa base, il est fréquent de
confondre les deux termes. Une molécule d'ARN contient, codée dans sa
séquence, l'information nécessaire au codage de la fonction d'une protéine
ou bien de sa propre fonction. Dans le premier cas, la molécule ne possède
pas de spécificité structurale. Dans le deuxième cas, elle a une structure
condensée spécifique qui détermine comment elle interagira avec d'autres
molécules et répondra aux conditions ambiantes (ARNs de transfert, ARNs
ribosomiques...). La molécule d'ARN se repliera alors sur elle-même en une
configuration 3D stable et fonctionnelle en formant des appariements
c'est-à-dire des interactions entre bases complémentaires (le plus souvent
A-U, G-C, G-U). On distingue pour l'ARN trois niveaux de représentation de
la structure. La structure primaire de l'ARN, ou séquence, désigne la
chaîne polyribonucléotidique orientée. La structure secondaire de
l'ARN désigne le repliement de la chaîne en un graphe planaire qui met en
évidence les liaisons covalentes et la plupart des interactions entre bases
complémentaires. Les sommets de ce graphe représentent les bases et les
arêtes représentent soit les liaisons covalentes, soit les interactions
entre bases. Ce repliement peut se décrire en termes de motifs structuraux :
extrémités terminales, boucles internes, boucles
multiples, épingles à cheveux, renflements, hélices
(cf. Figure 4).
= {A, U, G, C}, chaque
caractère étant spécifique de la base d'un nucléotide. Le type d'un
nucléotide étant entièrement caractérisé par sa base, il est fréquent de
confondre les deux termes. Une molécule d'ARN contient, codée dans sa
séquence, l'information nécessaire au codage de la fonction d'une protéine
ou bien de sa propre fonction. Dans le premier cas, la molécule ne possède
pas de spécificité structurale. Dans le deuxième cas, elle a une structure
condensée spécifique qui détermine comment elle interagira avec d'autres
molécules et répondra aux conditions ambiantes (ARNs de transfert, ARNs
ribosomiques...). La molécule d'ARN se repliera alors sur elle-même en une
configuration 3D stable et fonctionnelle en formant des appariements
c'est-à-dire des interactions entre bases complémentaires (le plus souvent
A-U, G-C, G-U). On distingue pour l'ARN trois niveaux de représentation de
la structure. La structure primaire de l'ARN, ou séquence, désigne la
chaîne polyribonucléotidique orientée. La structure secondaire de
l'ARN désigne le repliement de la chaîne en un graphe planaire qui met en
évidence les liaisons covalentes et la plupart des interactions entre bases
complémentaires. Les sommets de ce graphe représentent les bases et les
arêtes représentent soit les liaisons covalentes, soit les interactions
entre bases. Ce repliement peut se décrire en termes de motifs structuraux :
extrémités terminales, boucles internes, boucles
multiples, épingles à cheveux, renflements, hélices
(cf. Figure 4).
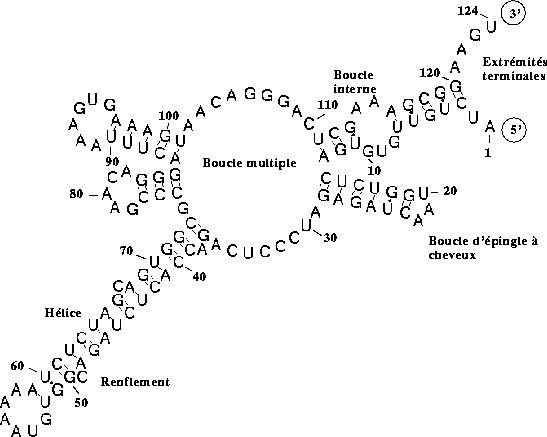
Figure 4: Structure secondaire d'un ARN. Le début de la séquence est
repérée par un << 5' >>.
La structure tertiaire de l'ARN fait explicitement référence au repliement dans l'espace de la chaîne polyribonucléotidique. Ce niveau de représentation est plus précis car il décrit l'organisation spatiale de la molécule au niveau atomique et plus complet car il contient des interactions supplémentaires par rapport à la structure secondaire.
Il est maintenant établi que la fonction d'une macromolécule (ARN ou protéine) est intimement liée à sa structure 3D. L'élaboration de modèles 3D de macromolécules est donc d'une importance majeure dans l'étude des relations structure-fonction. Radiocristallographie, Résonance magnétique nucléaire (RMN), modélisation moléculaire, chimie et génie génétique ouvrent actuellement de larges perspectives à la compréhension des relations structure-fonction et des mécanismes biologiques ainsi qu'au développement de la bio-ingénierie. La radiocristallographie et la RMN multidimensionnelle en particulier sont deux techniques utilisées pour déterminer la structure 3D des macromolécules biologiques, notamment celle des protéines.
Page suivante: 3 Cartographie
Niveau précédent: Satisfaction de contraintes et
Page précédente: 1 Introduction
Copyright(C)1995
INRA
Tous droits réservés