2022 : Les outils de l’intelligence artificielle se développent aussi à l’INRAE/MIAT
Les technologies de l’intelligence artificielle, qu’il s’agisse d’apprentissage profond, d’apprentissage automatique ou de raisonnement automatique, s’insinuent de plus en plus largement dans tous les domaines de la science. Leur maîtrise et la capacité de les adapter aux enjeux des systèmes complexes de la biologie à toutes les échelles, des molécules jusqu’aux populations, devient de plus en plus crucial pour l’INRAE. L’unité de mathématiques et informatiques appliquées de Toulouse, une unité du département MathNum, développe et utilise depuis longtemps des méthodes d’intelligence artificielle pour la biologie, l‘agronomie et l’environnement.
Cette année, elle a proposé deux nouvelles méthodes d’apprentissage automatique, motivées par des problématiques d’intégration de données complexes en biologie.
Ces deux contributions ont toutes les deux été acceptées pour publication dans un des supports les plus sélectifs du domaine de l’intelligence artificielle, l’International Conference on Machine Learning (ICML 2022).
Contexte et enjeux
la production de données expérimentales en biologie croît à une vitesse vertigineuse mais une des grandes difficultés réside dans leur utilisation optimale et leur intégration pour répondre à des problématiques ciblées dans le domaine de la santé, ou de l’environnement par exemple. Ces données peuvent être massives, hétérogènes et complexes. Leur analyse s’appuie de façon incontournable sur des outils issus des statistiques, de l’apprentissage automatique ou profond. Ces techniques, en plein révolution, doivent être adaptées, étendues ou réinventées pour être capables de répondre aux questions scientifiques des chercheurs d’INRAE, et au-delà.
Résultats
Investie depuis de longues années dans le développement, l’extension et l’application de méthodes statistiques, informatiques et d’intelligence artificielle pour le diagnostic, la conception ou la prise de décision dans les domaines de la biologie et de l’environnement, des molécules aux populations, l’unité MIAT a contribué cette année au développement de deux méthodes d’apprentissage automatique ciblées sur la modélisation et l’analyse de systèmes complexes. Ces deux méthodes ont été soumises à un des supports les plus sélectifs du domaine de l’intelligence artificielle (qui, comme l’informatique, publie ses résultats saillants dans des conférences très sélectives plus que dans des journaux): la conférence internationale d’apprentissage automatique (International Conference on Machine Learning, ou ICML’2022).
Perspectives
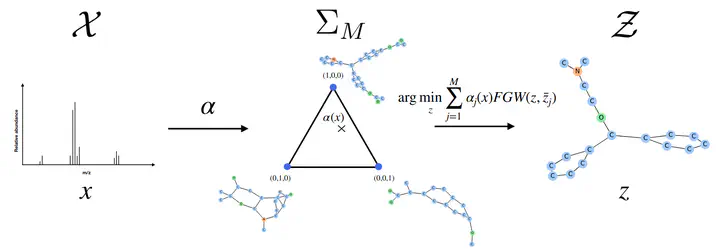
Les algorithmes proposés sont encore au stade de prototypes, déjà fonctionnels mais les progrès des algorithmes dans ce domaine sont incessants. Il faut donc continuer à les améliorer et les étendre pour traiter des problèmes toujours plus massifs et complexes et à les mettre en oeuvre sur des questions scientifiques d’intérêt. Pour l’algorithme proposé pour résoudre le problème de prédiction de graphes, une problématique scientifique d’intérêt concerne l’identification de nouvelles molécules à partir de données expérimentales.
Valorisation
Les outils sont accessibles sous la forme de logiciels open-source, accessibles sous GitHub. Une des méthodes publiées est d’intérêt direct pour le design de protéines. Elle est actuellement testée dans ce domaine sur différents problèmes de design, en combinaison avec des outils d’apprentissage profond.
Références bibliographiques
Valentin Durante, George Katsirelos, and Thomas Schiex. “Efficient low rank convex bounds for pairwise discrete Graphical Models.” Thirty-ninth International Conference on Machine Learning. 2022. Baltimore, USA.
Luc Brogat-Motte, Rémi Flamary, Céline Brouard, Juho Rousu, and Florence d’Alché-Buc. “Learning to predict graphs with fused Gromov-Wasserstein Barycenters.” Thirty-ninth International Conference on Machine Learning. 2022. Baltimore, USA.